The TOEFL Listen & Repeat Task:
A Data-Driven Analysis of Task Design, Collocation Load, and What Test-Takers Are Actually Being Measured On
Abstract
The TOEFL Listen & Repeat task looks simple on the surface: hear a sentence, repeat it once. In practice, it is doing much more. This paper analyzes the task using two sources: (1) the 2025 TOEFL iBT Technical Manual and (2) a dataset of 49 ETS sample prompts. The goal is to understand what the task measures, how prompts are constructed, and why learners succeed or fail.
The core finding is this: performance is not driven by word-by-word memory. It is driven by the ability to process, retain, and reproduce collocation chains under time pressure. Across 49 prompts, we observe 90 meaningful collocations, with density increasing sharply in later items (Q6–Q7). The scoring model supports this interpretation, emphasizing meaning preservation, intelligibility, and similarity to the prompt rather than exact reproduction.
The implication is practical. Most learners who “have a memory problem” actually have a chunking problem. And that distinction matters if you want to build useful feedback.
1. Introduction
Listen & Repeat sits at the foundation of the TOEFL Speaking section. It is short, structured, and highly controlled. It also carries more diagnostic information than most learners realize.
According to the technical manual, the Speaking section measures both foundational language skills and communication ability. Listen & Repeat specifically targets the ability to process spoken input and reproduce it accurately and intelligibly.
The task consists of seven prompts, delivered within a scenario, with increasing sentence length and complexity.
At first glance, this looks like a memory task. That interpretation breaks down quickly once you look at the data.
Research questions
2. What ETS is actually trying to measure
The TOEFL is not purely a communication test. It is a hybrid model.
The manual makes this explicit: the test combines foundational skills (vocabulary, syntax, processing) with communicative ability.
Listen & Repeat sits on the foundational side. But not in a trivial way.
It was included because:
- It provides rapid evidence of language proficiency
- It captures processing + production simultaneously
- It correlates with broader speaking ability
Construct breakdown
So already, “memory task” is too simple. This is a processing + retention + production task.
3. Anatomy of the task
ETS defines the structure clearly:
- 7 prompts
- Delivered in a scenario (e.g., campus, gym, library)
- Visual progression through the setting
- Sentences increase in length and complexity
Design logic
That last point matters. No second attempt means:
- No repair
- No restructuring
- No thinking time
You either processed the sentence correctly or you didn’t.
4. Data set
This paper uses:
- 7 ETS Listen & Repeat sets
- 49 prompts total
The contexts include:
- libraries
- gyms
- hotels
- nature reserves
- campus services
This matters because it drives lexical repetition patterns.
5. Collocation statistics
Using a strict definition (meaningful lexical chunks only), we identified:
- 90 collocations
- across 49 prompts
Distribution by position
So difficulty is not random. It is systematically built through chunk density.
6. The collocation architecture
This is where the task becomes interesting.
ETS is not building sentences from individual words. It is building them from reusable chunk families.
Top collocation families
Key insight
A “sentence” is typically:
3–4 collocation units chained together
Example structure:
- chunk 1: orientation
- chunk 2: location
- chunk 3: instruction
- chunk 4: condition or policy
That is what the learner is actually processing.
7. Why Q7 breaks people
The manual says later sentences are longer and more complex.
But length is not the real issue.
Real difficulty drivers
So when a learner says:
“I can’t remember long sentences”
What’s actually happening is:
- they lose chunk 3 or 4
- not the entire sentence
8. Scoring logic
The rubric is revealing.
A score of 4:
- allows changes
- as long as meaning is preserved
A score of 3:
- includes most content
- but meaning is not accurate
Score interpretation
Key takeaway
The test does not require perfect memory.
It requires:
- meaning preservation across chunks
9. Automated scoring
ETS uses:
- fluency
- intelligibility
- repeat accuracy
Feature layer
So even perfect memory won’t save you if:
- delivery collapses
- pronunciation obscures meaning
10. Reliability and validity
The Speaking section shows:
- reliability: 0.94
- human-machine agreement: 0.89
That is strong.
It means:
- the task is stable
- the scoring model is consistent
In other words, the test is not guessing.
11. Diagnostic implications
This is where things get interesting.
Most feedback today says:
“memory problem”
That’s not precise enough.
Better diagnostic model
This is where My Speaking Score adds real value.
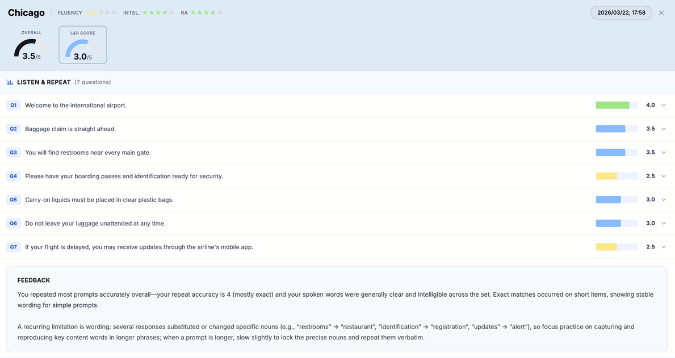
12. Conclusion
Listen & Repeat is not a memory drill.
It is a high-speed processing task built on collocation chains.
The evidence shows:
- structured progression
- increasing chunk density
- scoring based on meaning, not exact wording
- consistent statistical behavior
So the real skill is:
- hearing chunks
- retaining chunks
- reproducing chunks clearly
Or, in less academic terms:
You’re not remembering a sentence.
You’re rebuilding it in real time from pieces.
Appendix: Methods
Collocation definition
Counted:
- noun phrases (help desk)
- verb phrases (check the schedule)
- fixed expressions (on time)
Excluded:
- function word strings
- grammatical fillers
Data
- 7 ETS sets
- 49 prompts
Limitations
- sample prompts, not full operational bank
- collocation identification involves judgment
- does not include acoustic scoring features